Argo Workflows provides an excellent platform for infrastructure automation, and has replaced Jenkins as my go tool for running scheduled or event-driven automation tasks.
In growing my experience with Argo Workflows, I’ve killed clusters, broken workflows and generally made a mess of things. I’ve also built a lot of workflows that needed refactoring as they became difficult to maintain.
This blog post aims to share some of the lessons I’ve learned, and some of the patterns I’ve developed, to help you avoid the same mistakes I’ve made.
Lessons#
Configure Workflow TTL and Pod Garbage Collection#
Want to not kill your Kubernetes control plane? Then you should probably add this high up on the to-do list 😜.
Here’s the situation which gave me this lesson. I was looping over a list of items, executing a template for each. That template contained a DAG of about 50 steps. In total, I was getting to around 1500 pods for the entire workflow.
This was fine for a while until the list of items I was looping over got bigger, and then I started noticing some problems:
- The Argo Workflows UI was very slow/unresponsive when I was trying to view the workflow. This made troubleshooting issues very difficult.
- Some workflows with failing steps, which would retry, eventually got bigger than 1MB, which is the limit of objects in etcd. This causes errors like
Failed to submit workflow: etcdserver: request is too large. - Kubernetes was grinding to a halt due to the number of pods it was tracking. This wasn’t just active pods, this was pods in the
completedstate.
Tucked away in the cost optimization section of the Argo Workflows documentation:
Pod GC - delete completed pods. By default, Pods are not deleted.
Cool, I should have read that earlier 😅.
Recommendation#
First, make sure you persist workflow execution history, and all the logs, so that we can clean up the Kubernetes control plane without losing any information:
- Set up a Workflow Archive to keep a history of all workflows that have been executed.
- Set up an Artifact Repository, and set
archiveLogstotruein your Workflow Controller ConfigMap.
Next, in your Default Workflow Spec:
- Add a Workflow TTL Strategy, which controls the amount of time workflows are kept around after they finish. Clean up successful workflows quickly, and keep failed workflows around longer for troubleshooting.
- Add a Pod Garbage Collection strategy, which controls how long pods are kept around for after they finish. Use
OnPodCompletionto delete pods as soon as they finish inside the workflow. If you don’t, and you have a large or long-running workflow, you will end up with a lot of pods in thecompletedstate.
Also, don’t run massive workflows with 1500 pods, use the Workflow of Workflows Pattern instead.
If you really need big workflows and can’t use the Workflow of Workflow Pattern, you can also use the nodeStatusOffload feature.
Use a CronWorkflow to run synthetic tests#
Ever made a really small change, just a tiny little tweak to something in your cluster that would never break anything… and then it breaks something? Same.
Ever made a change, and then days or weeks later, a workflow that only runs once a month fails because of it? And you have no idea what caused it? And then have to dig into what the hell is going on? And then you find out it was that tiny little change you made weeks ago? And then you feel like an idiot? Same 😔.
Recommendation#
Use a CronWorkflow to simulate the behaviours of real workflows, without actually exciting the real thing. This allows us to test changes to our cluster, and see if they break anything before they break the real thing.
Here are some example behaviours you can exercise:
- Pulling specific containers
- Retrieving Secrets
- Assuming roles or identities (eg. Azure AD Workload Identity)
- Accessing resources over the network
- Writing artifacts and logs to the artifact repository
Schedule the workflow as often as makes sense for your use case.
Wrap the synthetic workflow(s) in an Exit Handler, allowing you to capture the results of the workflow (Succeeded, Failed, Error). In the exit handler, send telemetry to your monitoring system, and alert on it.
Also set up a “no data” alert, for when your tiny little tweak is to the observability stack, and you break that too 😬.
Patterns#
Parameter Output Facade#
Let’s say you have a situation where a tool inside a workflow step produces a JSON output like this, with the results of the job stored as parameter.output.result:
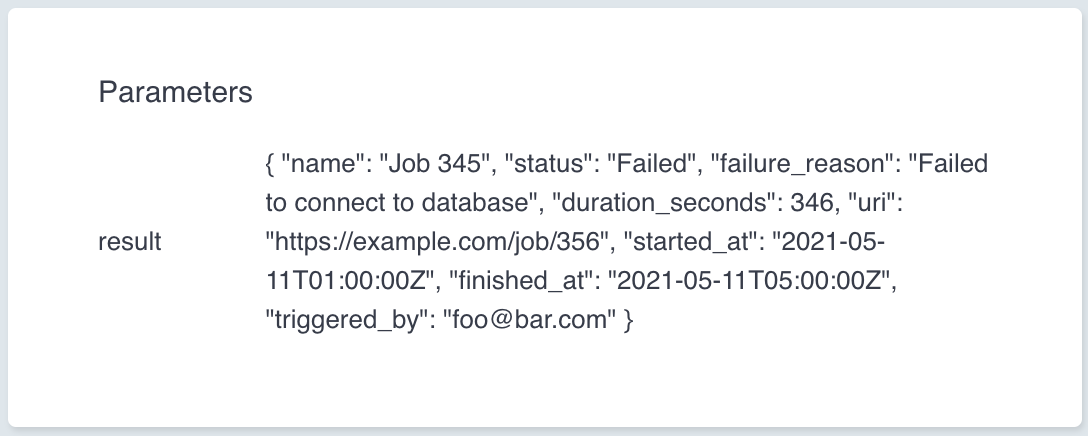
We have other teams that depend on this step to trigger their jobs. One team says they would like to be notified by email when the job fails, another wants Slack etc.
Here is what our current workflow looks like that they want to notify on:
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: generateName: job-dep-examplespec: entrypoint: main templates: - name: main steps: - - name: run-job template: run-job
# This template runs a theoretical job which produces a JSON output - name: run-job outputs: parameters: - name: result valueFrom: path: /tmp/result.json script: image: "python:3.12-alpine" command: - python source: | # Assume we can't control this JSON blob jsonResult = """{ "name": "Job 345", "status": "Failed", "failure_reason": "Failed to connect to database", "duration_seconds": 346, "uri": "https://example.com/job/356", "started_at": "2021-05-11T01:00:00Z", "finished_at": "2021-05-11T05:00:00Z", "triggered_by": "foo@bar.com" }""" file = open("/tmp/result.json", "w") file.write(jsonResult) file.close()How should we approach this, giving teams the information they need to handle their notification requirements?
The “Expression Destructure” example from the Argo Workflows examples gives us a hint to how we could do this:
# From https://github.com/argoproj/argo-workflows/blob/master/examples/expression-destructure-json.yamlapiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: generateName: expression-destructure-json- annotations: workflows.argoproj.io/version: ">= 3.1.0"spec: arguments: parameters: - name: config value: '{"a": "1", "b": "2", "c": "3"}' entrypoint: main templates: - name: main inputs: parameters: - name: a value: "{{=jsonpath(workflow.parameters.config, '$.a')}}" - name: b value: "{{=jsonpath(workflow.parameters.config, '$.b')}}" - name: c value: "{{=jsonpath(workflow.parameters.config, '$.c')}}" script: env: - name: A value: "{{inputs.parameters.a}}" - name: B value: "{{inputs.parameters.b}}" - name: C value: "{{inputs.parameters.c}}" image: debian:9.4 command: [bash] source: | echo "$A$B$C"This approach has a workflow taking a JSON object as input, and the properties that are needed are extracted using a jsonpath expression. While this would work, it’s not a good approach.
If the other teams that want notifications did this, it would create a coupling between their workflows and the structure of the JSON object. If the JSON object changes when we execute a job (eg. a field name change, different nesting levels), the teams depending on it would need to update their workflows, or they would get runtime errors.
To prevent this, we can use the Facade Pattern to create a simplified interface (a facade) to the JSON object. This allows us to hide the complexity of the JSON object from the dependent workflows (and teams), and allows it to change without breaking dependent workflows.
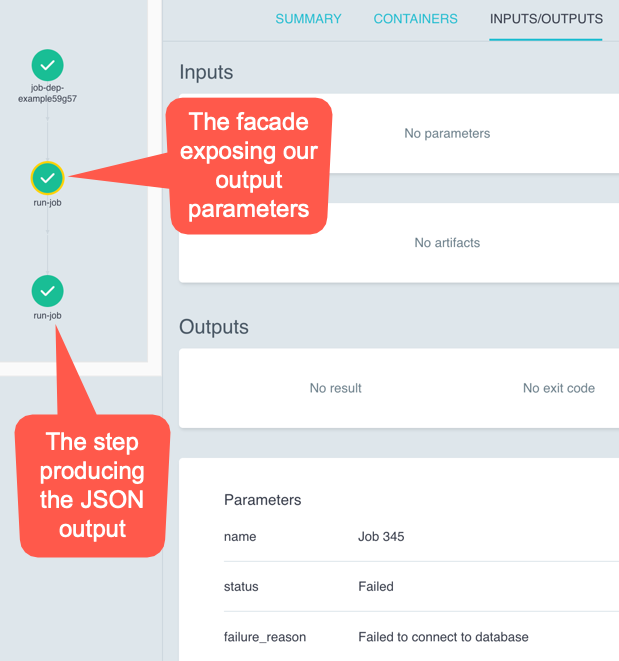
Let’s expose the following output parameters from our step to the other teams (thereby creating the facade):
parameter.output.name- The name of the jobparameter.output.status- The status of the job (FailedorSucceeded)parameter.output.failure_reason- The reason the job failed (or empty if the job succeeded)
This would allow other teams depending on this output to handle their own notifications by checking the status parameter, and the failure_reason parameter if the status is Failed.
(Keep in mind this is just an example, so the properties we are exposing are arbitrary.)
Here is how we can do it:
apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: generateName: job-dep-examplespec: entrypoint: main templates: - name: main steps: - - name: run-job template: run-job
# This is our `run-job` from before, we have just changed its name to make it clear # that it is internal to the workflow, and should not be used directly. - name: zz-internal-run-job outputs: parameters: - name: result valueFrom: path: /tmp/result.json script: image: "python:3.12-alpine" command: - python source: | # Assume we can't control this JSON blob jsonResult = """{ "name": "Job 345", "status": "Failed", "failure_reason": "Failed to connect to database", "duration_seconds": 346, "uri": "https://example.com/job/356", "started_at": "2021-05-11T01:00:00Z", "finished_at": "2021-05-11T05:00:00Z", "triggered_by": "foo@bar.com" }""" file = open("/tmp/result.json", "w") file.write(jsonResult) file.close() # This is our new `run-job` template, which uses the internal `zz-internal-run-job` # It is here that we create the facade that we want to expose as the interface to our users. # # Teams can now use this template, and get the result of the job as outputs. - name: run-job steps: - - name: run-job template: zz-internal-run-job outputs: parameters: - name: name valueFrom: expression: "jsonpath(steps['run-job'].outputs.parameters.result, '$.name')" - name: status valueFrom: expression: "jsonpath(steps['run-job'].outputs.parameters.result, '$.status')" - name: failure_reason valueFrom: expression: "jsonpath(steps['run-job'].outputs.parameters.result, '$.failure_reason')"Here are our outputs now:
Workflow of Workflows with Semaphore#
Workflow of Workflows is a well-documented pattern in the Argo Workflows documentation.
It involves a parent workflow triggering one or more child workflows. When you are looping over an item, and need to execute a workflow for each, this is where the pattern shines.
Pairing it with Template-level Synchronization, which allows you to limit the concurrent execution of the child workflows.
Here is an example of using the Workflow of Workflows pattern with:
- A
ConfigMapdefining the concurrency limit. - The semaphore using the
ConfigMap, limiting concurrent execution to1child workflow
---# This ConfigMap is used by the workflow to limit concurrent executionapiVersion: v1kind: ConfigMapmetadata: name: wow-semaphoredata: wow: "1"---apiVersion: argoproj.io/v1alpha1kind: Workflowmetadata: generateName: workflow-of-workflows-spec: entrypoint: main arguments: parameters: - name: json-list value: '["a", "b", "c"]' templates: - name: main steps: - - name: process-item template: process-json-item arguments: parameters: - name: item value: "{{item}}" withParam: "{{workflow.parameters.json-list}}"
- name: process-json-item inputs: parameters: - name: item # Usage of the ConfigMap specified above synchronization: semaphore: configMapKeyRef: name: wow-semaphore key: wow resource: action: create # This submits a child workflow, which will run as its own independent workflow in Argo. manifest: | apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: process-item- spec: entrypoint: whalesay templates: - name: whalesay container: image: docker/whalesay command: [cowsay] args: ["{{inputs.parameters.item}}"] successCondition: status.phase == Succeeded failureCondition: status.phase in (Failed, Error)Now we can see the parent workflow only allows one child workflow to run at a time, with the other workflows waiting patiently:
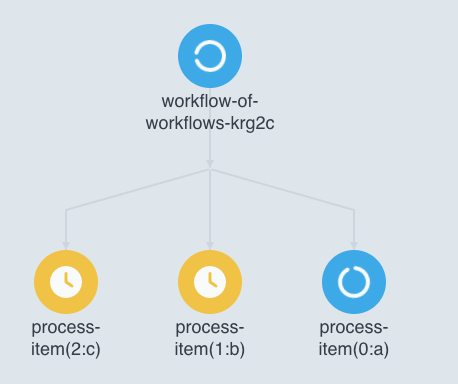
When using this pattern after you have configured workflow TTL and pod garbage collection, you will keep the number of pods running in the cluster to a minimum, which makes the Kubernetes control plane a little happier.
Workflow Injection#
The next pattern comes into play when you find yourself looping over the same list of items across multiple dependent workflows.
For our example, say we have a step which is enumerating all of our database instances in a cloud provider, and then executing a workflow for each database.
Of course, we want to leverage the Workflow of Workflows with Semaphore pattern to do this. Let’s look at how we might implement this. In the below example:
- There is a
WorkflowTemplatecalledget-dbswhich acts as the template that enumerates the databases. - There is a
WorkflowTemplatecalleddb-auditingwith the templateget-row-count-for-all-dbswhich enumerates the databases by referencingget-dbs, then executes the child workflow for each of the databases - The
get-row-count-and-logis the actual template we want executed for each database, which gets the row count for the database, and sends an event with the details.
---# This WorkflowTemplate enumerates all of our databases based on the environmentapiVersion: argoproj.io/v1alpha1kind: WorkflowTemplatemetadata: name: get-dbsspec: templates: - name: get-dbs inputs: parameters: - name: environment default: "dev" enum: ["dev", "prod"] outputs: parameters: - name: result valueFrom: path: /tmp/result.json script: image: "python:3.12-alpine" command: - python source: | # Depending on environment, return an array of databases import json import os if "{{inputs.parameters.environment}}" == "dev": dbs = ["a.dev.foo.bar", "b.dev.foo.bar", "c.dev.foo.bar"] elif "{{inputs.parameters.environment}}" == "prod": dbs = ["a.prod.foo.bar", "b.prod.foo.bar", "c.prod.foo.bar"] else: print("Invalid environment") os.exit(1) with open("/tmp/result.json", "w") as f: json.dump(dbs, f)---# This WorkflowTemplate uses the get-dbs template, and then spins up a child workflow for each using# the Workflow of Workflows with Semaphore patternapiVersion: argoproj.io/v1alpha1kind: WorkflowTemplatemetadata: name: db-auditingspec: templates: - name: get-row-count-for-all-dbs inputs: parameters: - name: environment enum: ["dev", "prod"] dag: tasks: # Get a list of all the dbs - name: get-dbs templateRef: name: get-dbs template: get-dbs arguments: parameters: - name: environment value: "{{inputs.parameters.environment}}" # Get the row count for each table in each db - name: get-row-count depends: get-dbs template: get-table-row-count-as-child-wfs arguments: parameters: - name: db-host value: "{{item}}" - name: db-name value: "main" - name: table-name value: "fruits" withParam: "{{tasks.get-dbs.outputs.parameters.result}}"
# Template for using the workflow in workflow pattern to run a child workflow for each item in the list - name: get-table-row-count-as-child-wfs inputs: parameters: - name: db-host - name: db-name - name: table-name synchronization: semaphore: configMapKeyRef: name: wow-semaphore key: wow resource: action: create manifest: | apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: get-row-count-{{inputs.parameters.db-host}}-{{inputs.parameters.db-name}}-{{inputs.parameters.table-name}}- spec: entrypoint: get-row-count-and-log arguments: parameters: - name: db-host value: "{{inputs.parameters.db-host}}" - name: db-name value: "{{inputs.parameters.db-name}}" - name: table-name value: "{{inputs.parameters.table-name}}" workflowTemplateRef: name: db-auditing successCondition: status.phase == Succeeded failureCondition: status.phase in (Failed, Error)
# Template to execute in the child workflow - name: get-row-count-and-log inputs: parameters: - name: db-host - name: db-name - name: table-name dag: tasks: - name: get-row-count template: get-table-row-count arguments: parameters: - name: db-host value: "{{inputs.parameters.db-host}}" - name: db-name value: "{{inputs.parameters.db-name}}" - name: table-name value: "{{inputs.parameters.table-name}}" - name: send-log-event depends: get-row-count template: send-log-event arguments: parameters: - name: message value: "Row count for {{inputs.parameters.db-host}} - {{inputs.parameters.db-name}} - {{inputs.parameters.table-name}} is {{tasks.get-row-count.outputs.parameters.rows}}"
- name: send-log-event inputs: parameters: - name: message script: image: "python:3.12-alpine" command: - python source: | print("Sending log event: " + "{{inputs.parameters.message}}") - name: get-table-row-count inputs: parameters: - name: db-host - name: db-name - name: table-name outputs: parameters: - name: rows valueFrom: path: /tmp/result.txt script: image: "python:3.12-alpine" command: - python source: | # Generate a random row count import random randomInt = random.randint(100, 10000) file = open("/tmp/result.txt", "w") file.write(str(randomInt)) file.close()If we decide we want to perform another operation against all the databases (eg. get the size of each database - get-database-size-and-log), we would need to re-implement the boxes in orange:

It just so happens that the parts we need to re-implement are also the more complex parts of the workflow:
- A DAG which first enumerates the databases using
get-dbs - The
withParamto loop over each database - The child workflow using the Workflow of Workflows with Semaphore
After we duplicate all of that, we can finally create the template which contains our new logic (get-database-size-and-log).
That’s where the Workflow Injection pattern comes in:
- We create an additional template called
for-each-dbinside theget-dbsWorkflowTemplate. This is the template that people can use when they want to run a workflow for each database. - The
for-each-dbtemplate handles looping over each database and executing the child workflow. It accepts the following parameters:workflow_template_ref- What is the name of theWorkflowTemplateto execute for each database?entrypoint- What is the entrypoint of theWorkflowTemplateto execute for each database?semaphore_configmap_name- What is the name of theConfigMapto use for the semaphore? This allows the caller to control the concurrency of the child workflows.semaphore_configmap_key- What is the key in theConfigMapto use for the semaphore? This allows the caller to control the concurrency of the child workflows.
- For each child workflow,
for-each-dbpasses indb-hostandenvironmentas inputs.
This moves all the complexity into the get-dbs WorkflowTemplate, making it easy for the caller to define a WorkflowTemplate that only considers execution against a single database. The callers’ workflow must accept db-host and environment as inputs.
The green boxes in this diagram show the logic of looping and executing a child workflow is now contained in the get-dbs WorkflowTemplate. The callers’ workflow is greatly simplified:

Here is the final workflow using this pattern:
---apiVersion: argoproj.io/v1alpha1kind: WorkflowTemplatemetadata: name: get-dbsspec: templates: - name: get-dbs inputs: parameters: - name: environment default: "dev" enum: ["dev", "prod"] outputs: parameters: - name: result valueFrom: path: /tmp/result.json script: image: "python:3.12-alpine" command: - python source: | # Depending on environment, return an array of databases import json import os if "{{inputs.parameters.environment}}" == "dev": dbs = ["a.dev.foo.bar", "b.dev.foo.bar", "c.dev.foo.bar"] elif "{{inputs.parameters.environment}}" == "prod": dbs = ["a.prod.foo.bar", "b.prod.foo.bar", "c.prod.foo.bar"] else: print("Invalid environment") os.exit(1) with open("/tmp/result.json", "w") as f: json.dump(dbs, f) - name: for-each-db inputs: parameters: - name: environment default: "dev" enum: ["dev", "prod"] - name: workflow_template_ref - name: entrypoint - name: semaphore_configmap_name - name: semaphore_configmap_key dag: tasks: - name: get-dbs template: get-dbs arguments: parameters: - name: environment value: "{{inputs.parameters.environment}}" - name: for-each-db depends: get-dbs template: zz-internal-child-workflow arguments: parameters: - name: db-host value: "{{item}}" - name: environment value: "{{inputs.parameters.environment}}" - name: workflow_template_ref value: "{{inputs.parameters.workflow_template_ref}}" - name: entrypoint value: "{{inputs.parameters.entrypoint}}" - name: semaphore_configmap_name value: "{{inputs.parameters.semaphore_configmap_name}}" - name: semaphore_configmap_key value: "{{inputs.parameters.semaphore_configmap_key}}" withParam: "{{tasks.get-dbs.outputs.parameters.result}}"
- name: zz-internal-child-workflow inputs: parameters: - name: db-host - name: environment - name: workflow_template_ref - name: entrypoint - name: semaphore_configmap_name - name: semaphore_configmap_key resource: action: create manifest: | apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: # Tidy up the names to make them safe for generating child workflow names generateName: child-{{inputs.parameters.environment}}--{{inputs.parameters.db-host}}- spec: entrypoint: "{{inputs.parameters.entrypoint}}" arguments: parameters: - name: db-host value: "{{inputs.parameters.db-host}}" - name: environment value: "{{inputs.parameters.environment}}" workflowTemplateRef: name: "{{inputs.parameters.workflow_template_ref}}" successCondition: status.phase == Succeeded failureCondition: status.phase in (Failed, Error) synchronization: semaphore: configMapKeyRef: name: "{{inputs.parameters.semaphore_configmap_name}}" key: "{{inputs.parameters.semaphore_configmap_key}}"---apiVersion: argoproj.io/v1alpha1kind: WorkflowTemplatemetadata: name: db-auditingspec: templates: - name: main inputs: parameters: - name: environment default: "dev" enum: ["dev", "prod"] steps: - - name: for-each-db templateRef: name: get-dbs template: for-each-db arguments: parameters: - name: environment value: "dev" - name: workflow_template_ref value: "db-auditing" # This workflow template - name: entrypoint value: "get-row-count-and-log" - name: semaphore_configmap_name value: wow-semaphore - name: semaphore_configmap_key value: wow
- name: get-row-count-and-log inputs: parameters: - name: db-host - name: environment - name: db-name value: "main" - name: table-name value: "fruits" steps: - - name: get-row-count template: get-table-row-count arguments: parameters: - name: db-host value: "{{inputs.parameters.db-host}}" - name: db-name value: "{{inputs.parameters.db-name}}" - name: table-name value: "{{inputs.parameters.table-name}}" - - name: send-log template: send-log-event arguments: parameters: - name: message value: "Row count for {{inputs.parameters.db-host}} - {{inputs.parameters.db-name}} - {{inputs.parameters.table-name}} is {{steps.get-row-count.outputs.parameters.rows}}"
- name: send-log-event inputs: parameters: - name: message script: image: "python:3.12-alpine" command: - python source: | print("Sending log event: " + "{{inputs.parameters.message}}") - name: get-table-row-count inputs: parameters: - name: db-host - name: db-name - name: table-name outputs: parameters: - name: rows valueFrom: path: /tmp/result.txt script: image: "python:3.12-alpine" command: - python source: | # Generate a random row count import random randomInt = random.randint(100, 10000) file = open("/tmp/result.txt", "w") file.write(str(randomInt)) file.close()Conclusion#
I hope applying the suggestions from the lessons and patterns above will help you avoid some of the pitfalls I’ve encountered while using Argo Workflows.
If you have any questions or feedback or would like to talk about your experiences with running Argo Workflows in production, you can reach me on Twitter / X.